|
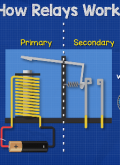
[综合] 关于端到端自动驾驶的四个常见误区 |
|
汽车零部件采购、销售通信录 填写你的培训需求,我们帮你找 招募汽车专业培训老师
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
 |手机版|小黑屋|Archiver|汽车工程师之家
( 渝ICP备18012993号-1 )
|手机版|小黑屋|Archiver|汽车工程师之家
( 渝ICP备18012993号-1 )
GMT+8, 29-5-2026 07:48 , Processed in 0.432886 second(s), 50 queries .
Powered by Discuz! X3.5
© 2001-2013 Comsenz Inc.
 深度剖析 2019-2020 概念车设计趋势
深度剖析 2019-2020 概念车设计趋势 智能座舱演进的思考
智能座舱演进的思考




 IP卡
IP卡 狗仔卡
狗仔卡 发表于 21-5-2024 20:20:42
发表于 21-5-2024 20:20:42








 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡